Hi community -
I’m having trouble figuring out what the best way might be to handle this in Nextflow and somehow i never came upon this issue before:
Let’s say I have process1, process2, and process3 where process2 is dependent on the output of process1 and process3 is dependent on the output of process2. And let’s say the input to process1 has 10 elements (so process1 gets executed 10 times).
What i’m looking to avoid is process1 running 10 times in a row without executing process2 and process3; I’d like process2 and process3 executed first before it moves onto the second call of process1.
Is there a feature that would handle this in Nextflow or a recommended best practice for dealing with this situation?
Best Regards,
Steve
Edit: I’m already hip to maxForks but it still doesn’t stop 10 sequential process1 calls. process1 is downloading a lot of data and i was hoping to have it deleted after some downstream stuff runs.
Hi @stephen_mclaughlin,
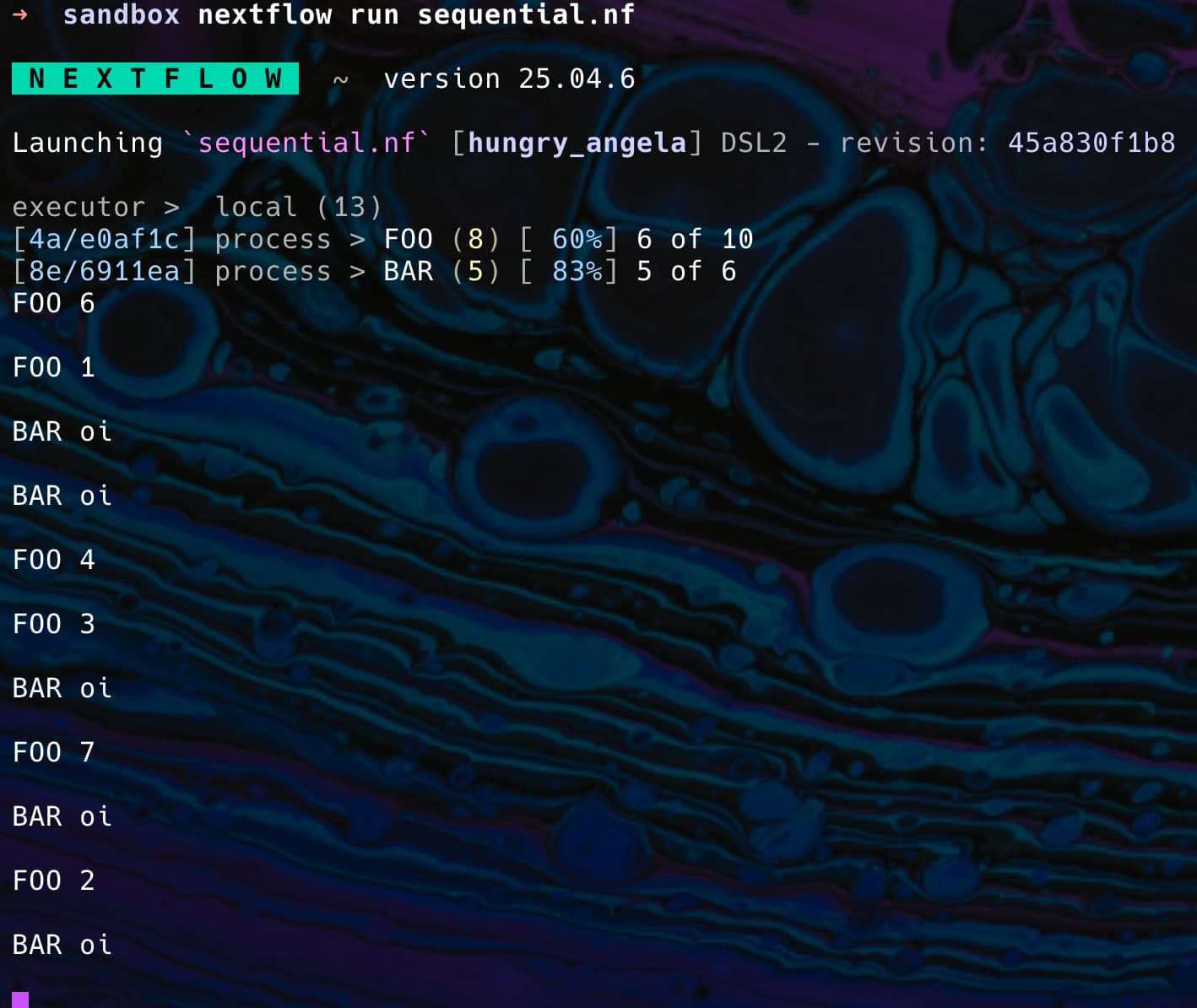
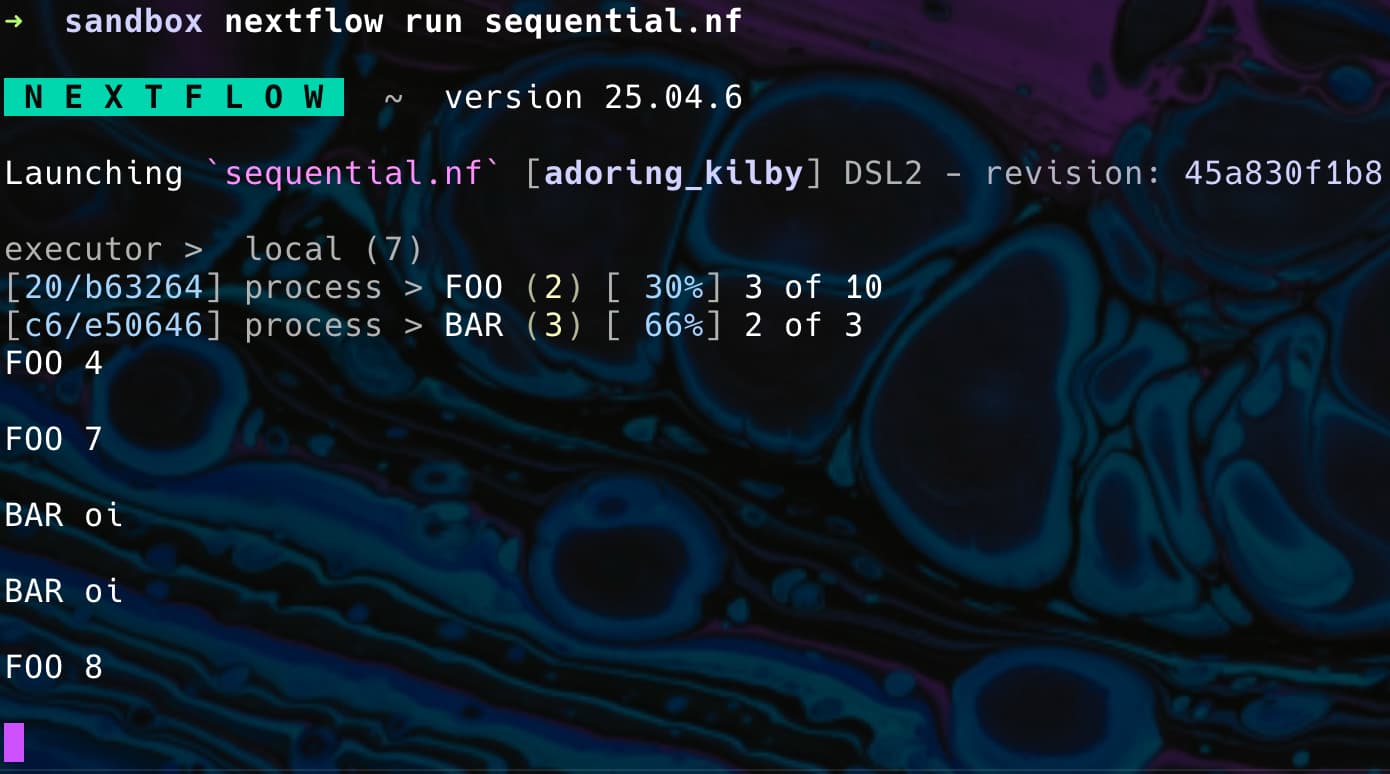
I’m not sure if I understood what you’re looking for, as maxForks should help you with that. See the snippet below:
process FOO {
maxForks 1
debug true
input:
val ch_input
output:
val 'oi'
script:
"""
echo 'FOO ${ch_input}'
sleep 5
"""
}
process BAR {
debug true
input:
val some_input
script:
"""
echo 'BAR ${some_input}'
sleep 5
"""
}
workflow {
ch = Channel.of(1..10)
FOO(ch)
BAR(FOO.out)
}
I can’t upload a video here, but every time a FOO task was finished, a BAR task started. If you run the code above on your machine, you should see FOO 2 of 10 and BAR 1 of 10. FOO 3 of 10 and BAR 2 of 10, and so on.
See:
Hi Marcel,
Thanks for the reply! Maybe you’re right that maxForks will help me, but it didn’t seem that way to me at the time I wrote this up. What I was interested in doing is downloading some large files in process1, performing some operations on them in multiple processes (i.e. process2-6) and finally deleting them by process7 because they are so large that if too many accumulate my diskspace fills up. Since there’s some benefit in processing them simultaneously as I have multiple processors (I’m running Nextflow in local mode with 8 CPU) I wanted to parallelize them in batches i.e. 8 files at a time. Is it the cases that if each process had maxForks 8 I could achieve this goal? It’s a bit unclear to me what effect that would have on the sequence of process execution. I was under the impression maxForks 1 would prevent more than 1 of the FOO processes from running simultaneously, but wouldn’t necessarily have an effect on the sequence of execution which would be mostly up to random chance. Is that a misunderstanding of maxForks on my part?
Best,
Steve
If you set cpus 8, depending on your compute environment (e.g., a cluster with a workload manager), Nextflow will try to use these 8 CPUs if required. If you want to limit the parallelization of tasks per process, you use maxForks. If you want to control order (make sure the first process instance, a task, finishes first, then the second, and so on, also known as fair threading), you use the fair process directive.
As for cleaning the work directory (downloaded files), the only native option we provide for now is cleanup upon finishing the run successfully, which is not very helpful for you. However, the nf-boost plugin offers cleaning up the work directory on the fly and is exactly what you need to fight this disk usage situation.
Two other things that may be useful to you: Whenever you want to control process flow that is not tightly input-output linked, you can use value signals (or state dependency). If, for some reason, you want to handle multiple samples (or tasks) in a single task (process instance), you can use task batching. Task batching is useful when you need to move lots of files because tasks are run in different places. By running a bunch of them together, you decrease the number of downloads of files moving around in a cloud environment.
Not saying all this is useful for this specific situation you’re in, but I think it’s worth presenting them so that you can see what fits better your case.
Appreciate the tips! I did end up using task batching to process things in groups and delete when i was done, but I had a monolithic process do_everything to make sure I could download –> process –> and delete in batch sizes that were managable for diskspace. Not ideal or very elegant, but I still got my job done and benefited from Nextflow job reuse since it ran for 9+ days and needed to be interrupted several times. I’ll consider these other solutions for when I do something like this again.