Hello,
We get many "WARN nextflow.processor.PublishDir - Failed to publish file:" messages in our .nextflow.log files. I understand that in the new version of Nextflow we can add the failOnError option for the publishDir directive Process reference — Nextflow documentation which will automatically fail the pipeline on these publish failures and you will have to resume the pipeline to get the rest of the files. There are also some options for exponential backoff with jitter with the workflow.output.retryPolicy.* Configuration options — Nextflow documentation set of options but this appears to be an approach to completely replace the publishDir directive. Please keep me honest if you disagree?
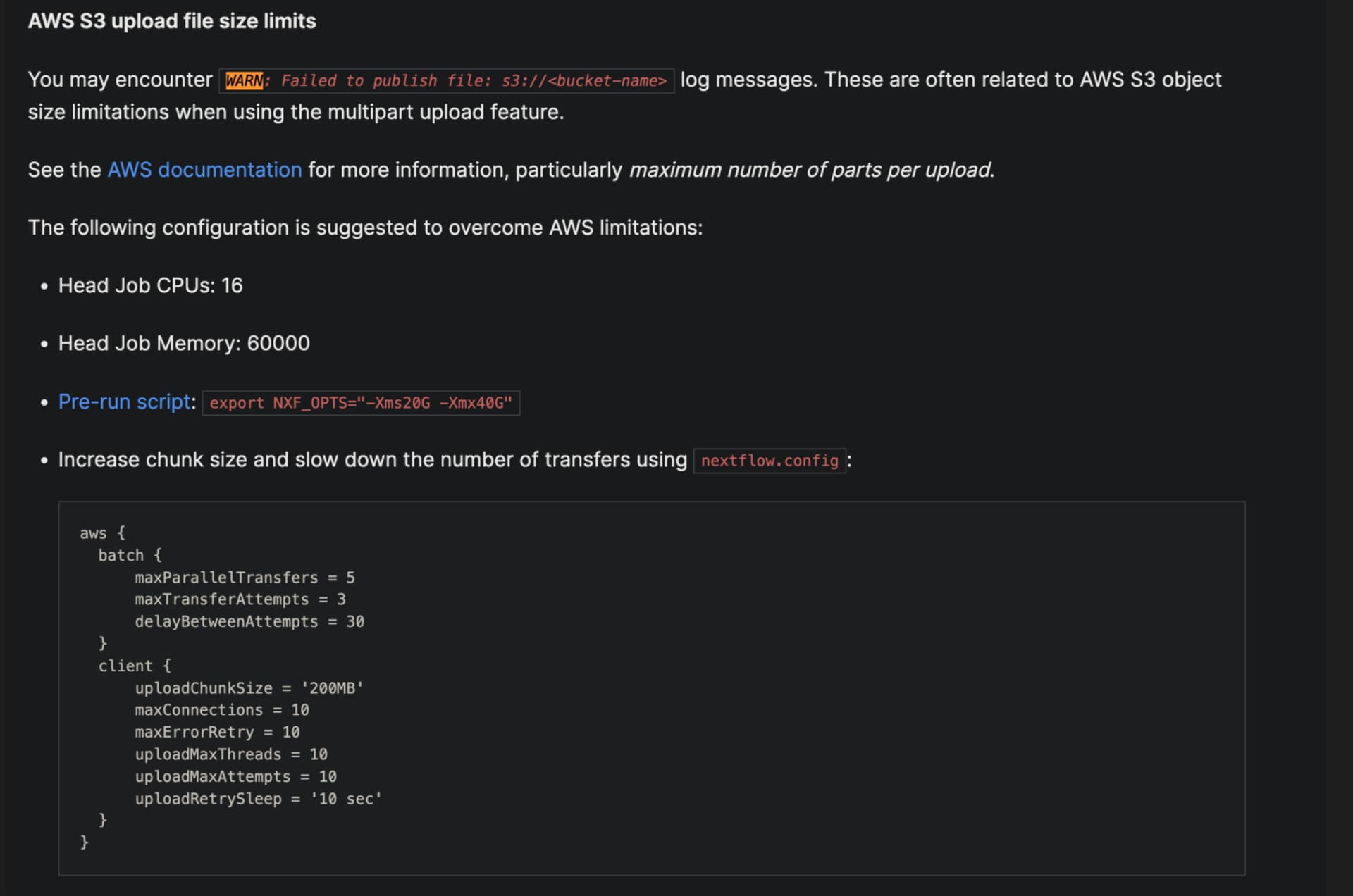
Since we have production pipelines at our company and don’t want to upgrade the nextflow version and replace the publishDir directive just yet, Do you have any thoughts on how best we should tweak our aws.client configuration option values in our nextflow.config specifically uploadChunkSize, maxConnections, and uploadMaxThreads which appear to be used by the nextflow control process where the pipeline is launched from to publish files from the working directory to the output directory?
Our values today are
uploadChunkSize = ‘100MB’ // The size of a single part in a multipart upload; default
maxConnections = 5 // The maximum number of allowed open HTTP connections; default:10
uploadMaxThreads = 5 // The maximum number of threads used for multipart upload; default:10
The Seqera documentation Nextflow | Seqera Docs points at below but not sure if this is valid for us (we already use an instance with those specs):